Clustering problem
Clustering in data mining refers to the grouping of data points within a dataset based on their similar properties. Data points within a cluster are highly similar to each other and can be discriminated from data points within other clusters. Successful clustering, therefore, maximizes both the compactness of data points within a cluster and the discrimination between clusters.
Given a set of n objects X = {x1, x2,…,xn}, let Θ = {U, V}, where cluster set V = {v1, v2,…,vc} and partition matrix U={uki}, k=1,…,c, i=1,…,n, be a partition of X such that 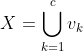 ,
,
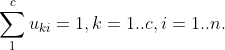
Each subset vk of X is called a cluster and {uki} is the membership degree of {xi} to vk. uki ∈ {0,1} if Θ is crisp partition, otherwise, uki ∈ [0,1]. The goal of cluster analysis is to assign objects to clusters such that objects in the same cluster are highly similar to each other while objects from different clusters are as divergent as possible. These sub-goals create what we call the compactness and separation factors that are used, not only for modelling the clustering objectives, but also for evaluating the clustering result. These two parameters can be mathematically formulated in many different ways that lead to numerous clustering models.
 An object data matrix X
An object data matrix X A dataset containing the objects to be clustered is usually represented in one of two formats, the object data matrix and the object distance matrix. In an object data matrix, the rows usually represent the objects and the columns represent the attributes of the objects regarding the context where the objects occur. The roles of the rows and columns can be interchanged for another representation method, but this one is preferred because the number of objects is always enormously large in comparison with the number of attributes. Assume we have n objects in a p-dimension data space. The object data matrix X then has n rows and p columns where xij is the attribute of object i in the jth dimension and xi is the vector (or object vector) of object i across p dimensions. The distance matrix contains the pairwise distance (or dissimilarity) of objects. Specifically, the entry (i,j) in the distance matrix represents the distance between objects i and j, 1≤i,j≤n. The distance of objects i and j can be computed using the object vectors i and j from the object data matrix based on a distance measurement. However, the object data matrix cannot be fully recovered from the distance matrix, especially when the value of p is unknown. REFERENCES
- Thanh Le (2013) A Machine Learning approach for Gene Expression analysis and applications.